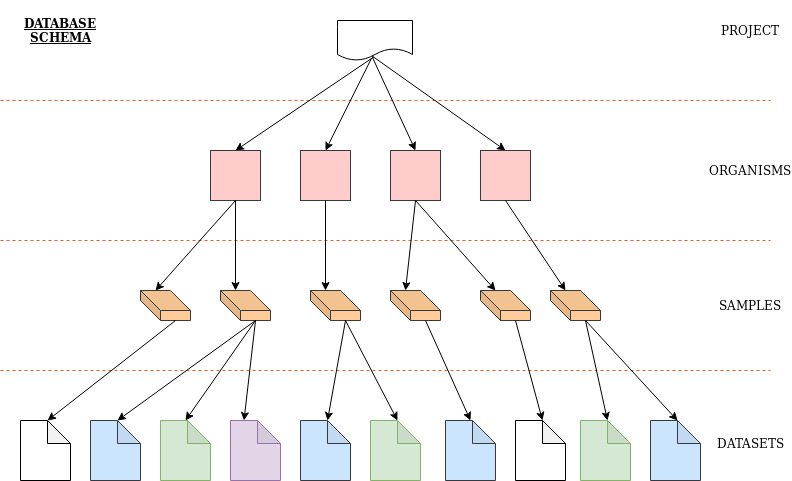
MSD Database Structure
MSD database has a hierarchical structure. We have the concepts of Projects, Organisms, Samples, and Datasets. As a user has defined a project, the new project can host various organisms, samples and datasets. A defined organism can have several samples assigned to and similarly each sample might have various datasets.
Imgaine this hypothetical situation: research project in featuring three mice. In this case each mouse would be an organism at MSD. Suppose it is important to compare two types of samples (colon biopsy and feces) and two microbiome analysis methods (16S amplicon and Shotgun sequencing). In order to achieve this it is required to attempt one sampling for each sample type and get enough sample for each sample type to send for different sequencing methods. It means that 2 samples from each mouse will be taken and from each sample 2 datasets would be produced. Thus, all three mice should be defined as organism at MSD and for each of them only 2 samples are defined for which 2 datasets would get generated and uploaded to MSD. The table below shows the case.
The table above shows that each mouse has 4 samples and each sample has 2 datasets. In total, there are 12 datasets.
MSD IDs Explanation
In MSD database, each entity has a unique ID. This ID is used to identify the entity in the database. For example, a project has a unique ID, an organism has a unique ID, a sample has a unique ID, and a dataset has a unique ID called MSD ID. Taking the example in MSD Database Structure, we have 12 datasets in total for their corresponding project. According MSD Database Structure, these 12 datasets should belong to some samples and some organisms and ultimately to a project. For each entity in the table Relation of entities at MSD, there is a unique ID. The table below shows the unique IDs for each entity.
Datasets ID prefix
Various datasets types in MSD have different prefixes. For example, 16S amplicon datasets have a prefix D and shotgun datasets have a prefix DM. This is to differentiate between different types of datasets.
Dataset Type |
ID Prefix |
|---|---|
16S amplicon dataset |
“D” |
Metagenomics (i.e: shotgun) dataset |
“DM” |
Targeted metaboloimcs dataset |
“DTM” |
Untargeted metaboloimcs dataset |
“DUM” |
Metatranscriptomics dataset |
“DTR” |
Metaproteomics dataset |
“DPR” |
Note
Definition of a sample refers to each attempt of sampling. For example, two samples, both taken from feces, at the same time point would be considered two distinguished samples so that two different sample objects at MSD.